Healthcare R&D Improved far field speech recognition with microphone arrays Innovation at Nuance | Employee Guest Blogger May 2, 2022
Innovation & Research How our engineers are creating an automation Center of Excellence Nuance Guest Blogger February 10, 2022
Enterprise R&D Data augmentation for real-world multi-channel speech recognition Innovation at Nuance | Employee Guest Blogger December 8, 2021
Enterprise R&D Combining the advantages of close-talk and far-talk speech recognition Innovation at Nuance | Employee Guest Blogger December 6, 2021
Healthcare R&D Improving named entity speech recognition accuracy Innovation at Nuance | Employee Guest Blogger September 1, 2021
Healthcare R&D Improving automatic speech recognition from distant microphones using self-attention Innovation at Nuance | Employee Guest Blogger August 31, 2021
Customer engagement Kicking the digital front door open Brenda Hodge | Chief Marketing Officer August 3, 2021
Innovation & Research Nuance wins six Stevie® American Business Awards for excellence in technological innovation Brenda Hodge | Chief Marketing Officer May 11, 2021
Enterprise R&D Delivering non-intrusive signal intelligence with deep learning Innovation at Nuance | Employee Guest Blogger January 13, 2021
Innovation & Research Reducing the human labeling effort for training end-to-end speech recognition Innovation at Nuance | Employee Guest Blogger October 23, 2020
Enterprise R&D Making speech recognizers more robust in the wild Innovation at Nuance | Employee Guest Blogger January 13, 2020
Enterprise R&D Delivering personalized user experiences with speaker adapted end-to-end speech recognition Innovation at Nuance | Employee Guest Blogger December 20, 2019
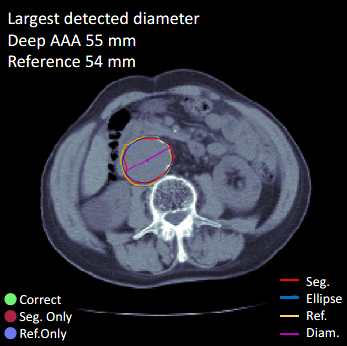
Healthcare R&D DeepAAA: Detecting Abdominal Aortic Aneurysms with deep learning Innovation at Nuance | Employee Guest Blogger December 19, 2019